Cloud Field Day 14 had some great presentations around controlling cloud storage, data, and networks. I made some predictions on what was going to be presented in my previous blog and for the most part they were all touched upon, granted some more than others. The standard was high, and I would encourage people to check out the presentations. Before I discuss some of my key takeaways from the event below, I would like to offer a huge thanks to Stephen Foskett, his team, fellow delegates along with the presenters, for taking the time to not only present, but answer delegate questions. Its always a fun event and that takes effort!
Has storage recently become software?
No, the concept of Software Defined Storage (SDS) has been around for over a decade now. We have been able to provision and define storage for quite some time, using software policies and commands to abstract what’s happening at the hardware layer. Historically this was as simple as defining a RAID group using multiple drives to present a LUN. Complexity and performance grew when we added tiering slow drives with faster ones leading to the obvious additional tier of solid state.
These tiers were provisioned independently or combined into a pool with vendors building in some smarts around data placement depending on activity. Storage vendors differentiated themselves on how well they were able to perform this function. Variance was decided on performance, scalability, features, and price. Storage vendors made relationships with hardware vendors to provide their own individual edge using faster CPUs, more RAM, better connectivity, and reliability. The value add was the appliance package and the software and interface to control the hardware within.
So, What if Anything Has Changed?
Nothing, apart from the whole cloud adoption thing. You cannot buy an array from your preferred storage vendor and ship it to a hyper scaler, even if you could, why would you want to? It goes against the cloud operating model from a financial perspective aside from the logistical impossibilities. This created a divide between how you did storage on prem vs the public cloud. Change has recently come, in how historical storage companies have pivoted to become cloud companies. Extending their stack and feature sets into the public cloud. Hybrid multi-cloud is now a possibility potentially working with the same vendors you use for your on prem stack, albeit in the public clouds.
This is a big deal.
Why is this a big deal?
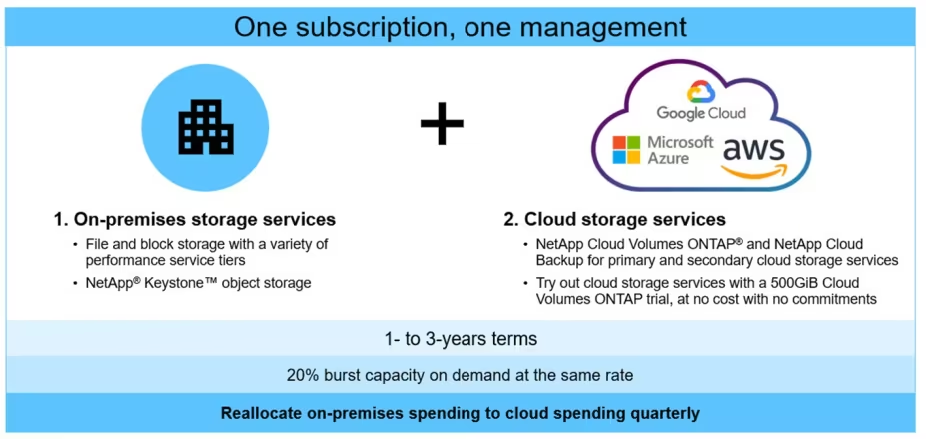
Enterprises move slow and are either carrying significant technical debt and/or engineering familiarity with their preferred vendor. Cloud native approaches have brought about new ways of doing things, many enterprises invested in the people and technologies required to do this effectively, but not all are as far along. Trusted vendors offering customers, help with the complexities around managing a hybrid cloud will be very attractive options. For example, Amazon FSx for NetApp ONTAP lets you use the technologies you have been using for years to manage data better in AWS, and soon Azure and Google.
Furthermore, NetApp are giving customers Cloud Manager to help alleviate and consolidate issues with managing aspects of the hybrid multi-cloud. One thing evident is the fact that companies want alternatives to native cloud storage.
What About Cloud Native Options?
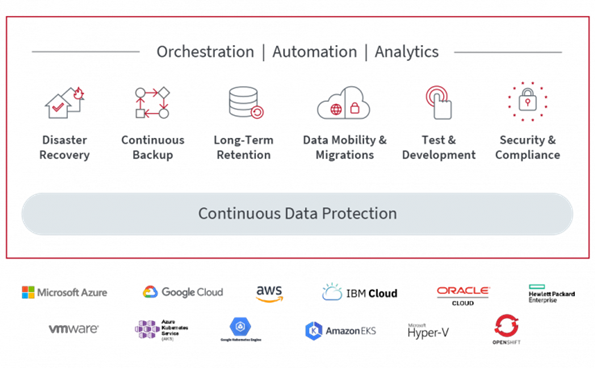
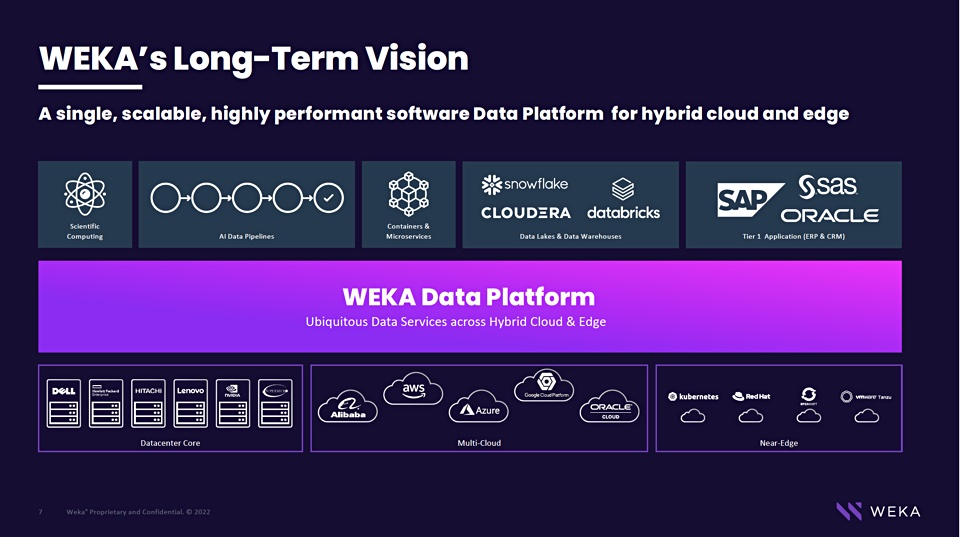
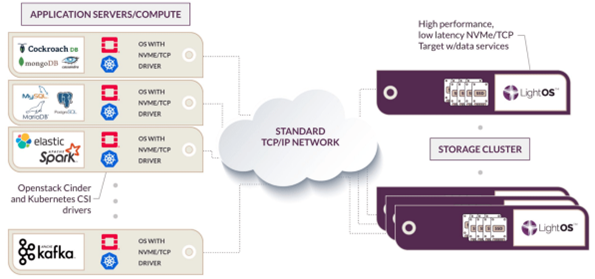
Well, we saw a few good options there too, Weka and Lightbits presented some amazing options to scale performance massively in multiple clouds using relatively hardware agnostic options. This is a similar shift from traditional storage vendors moving away from selling hardware and software to realise business outcomes. Whilst all storage companies have the ability to provide both on prem and cloud based storage they are coming at it from different angles. If you want a polished product to present file or object based storage, Weka offers a cloud file system offering NFS, SMB and S3 compatible. Lightbits have taken a different approach offering block NVMe over TCP delivering more of a storage engine to do block very well at scale within the public clouds or on prem. Both companies leverage hardware provided by a 3rd party and play well with various Intel accelerators.
What about Cloud Management?
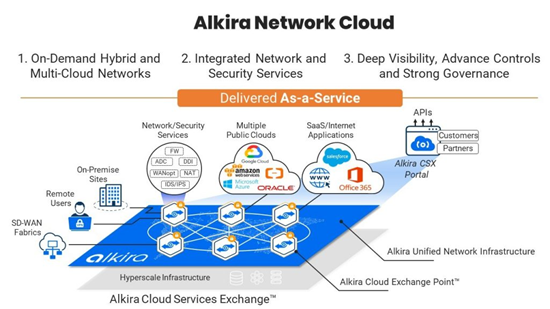
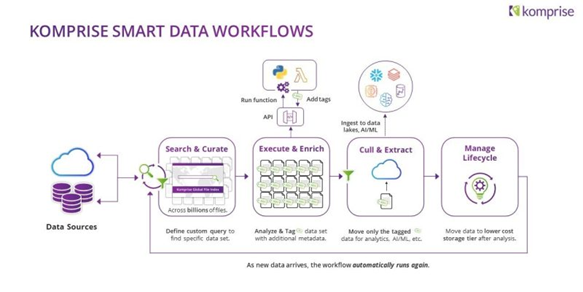
We saw great presentations from Zerto, Morpheus, Alkira and Komprise all offering different ways of effectively managing clouds. Abstracting multiple clouds was a recurring theme however they all had their own specific areas of focus and can add value to many enterprises. Abstraction is a common theme for companies right now increasing the control and visibility of elements under a given solutions scope. As the ever-increasing number of layers of abstraction continues to grow, aggregation tools add value centralising operations in developer friendly ways leveraging the plethora of API’s available often trying to wrap them up under one.
What’s the takeaway?
Vendors are providing ever increasing ways to control your hybrid cloud infrastructures. Alkira offered something I have not seen before covering the network layer, something I imagine we will see more of in future. Visibility and control are the drivers leveraging existing relationships with legacy storage providers and/or public clouds but the overall theme was heavily centralised on getting multiple clouds working better together, no bad thing.
As well as reviewing social media using the #CFD14 hashtag you can watch Cloud Field Day 14 content here:
https://techfieldday.com/event/cfd14/
-Craig Rodgers